本文所有 Python 代码依赖:
numpypandasmatplotlibseabornscipyyfinance。执行pip install numpy pandas matplotlib seaborn scipy yfinance即可复现全部结果。
一、蒙特卡洛是什么
蒙特卡洛这个名字来自摩纳哥的著名赌场——一个充满随机性的地方。蒙特卡洛模拟的本质也正是利用随机性:当你面对一个确定性方法无法解决(或太复杂)的问题时,用大量随机采样来逼近答案。
1946 年,物理学家 Stanislaw Ulam 在病床上玩纸牌时突然想到:想知道一副牌赢的概率,与其试图精确计算排列组合,不如模拟一万次发牌然后统计结果。后来他和冯·诺依曼一起用这种方法研究核反应堆中的中子输运问题。从此,这套方法有了一个优雅的名字。
扔针算 π
蒙特卡洛最经典的入门例子是估算 :
- 在一个边长为 2 的正方形内画一个半径为 1 的内切圆
- 随机向正方形中撒点
- 统计落在圆内的比例
- 该比例 4 = 的估计值
import numpy as np
n = 50000
inside = 0
for _ in range(n):
x, y = np.random.uniform(-1, 1, 2)
if x**2 + y**2 <= 1:
inside += 1
pi_est = 4 * inside / n
print(f"π 估计值: {pi_est:.6f} (真实值: {np.pi:.6f})")这个例子里,真实模型是”点在圆内”,但我们不需要推导任何数学公式——只需要反复抽样、计数、取均值。
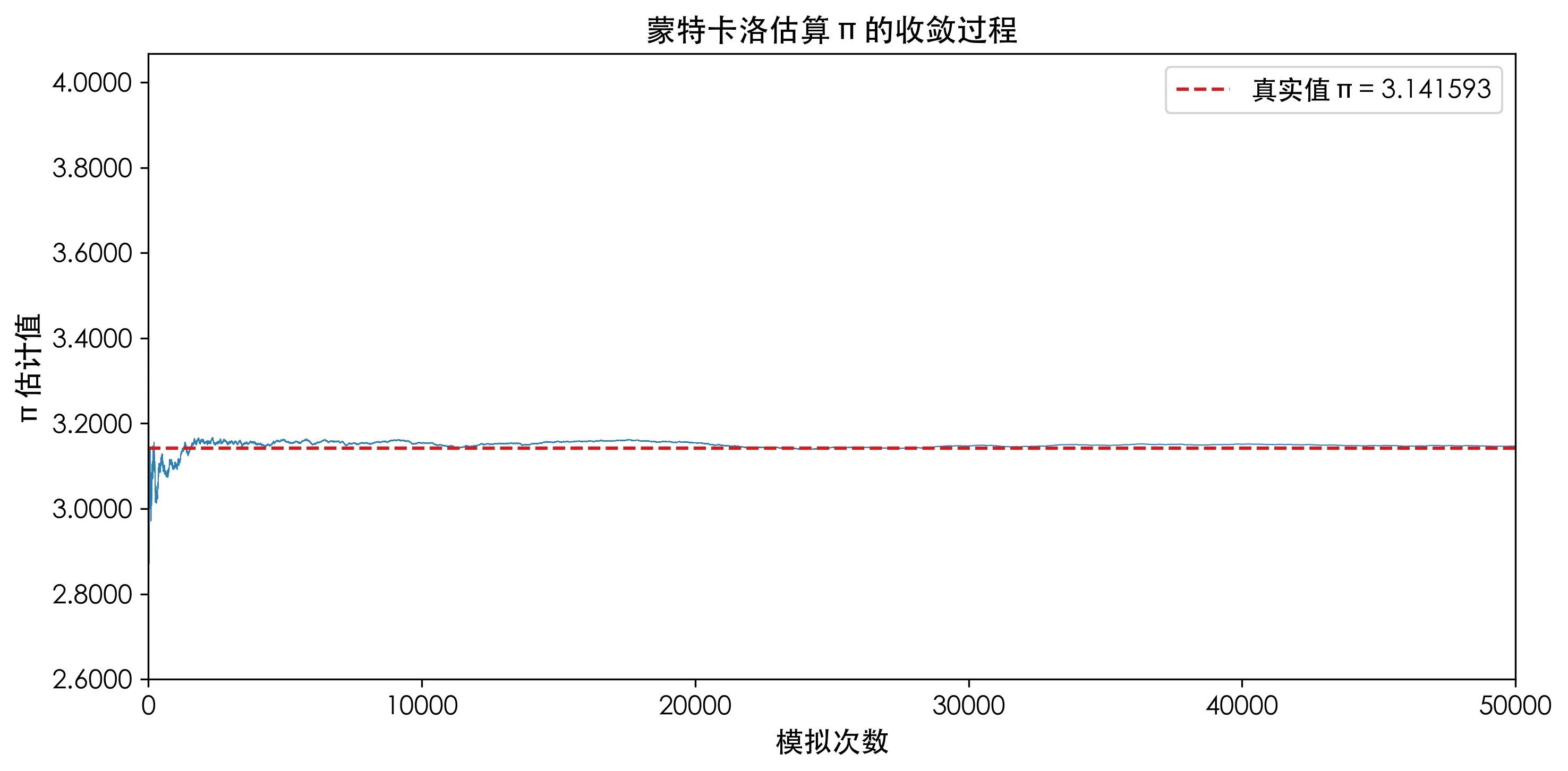
为什么有效:大数定律
蒙特卡洛模拟的理论根基是大数定律(Law of Large Numbers):
直观理解:撒的点越多,样本均值越接近真实期望值。从上面的收敛图可以看到,一开始 π 的估计在 ±0.5 范围内波动,到 10,000 次以后基本稳定在 3.14 附近。
蒙特卡洛的核心工作流可以概括为三步:
确定性模型(算不出来)
↓
随机采样 × N 次
↓
统计结果(逼近真实答案)当你理解了这一步,“蒙特卡洛”就从一个吓人的专业术语变成了一件趁手的工具箱。接下来我们看它在金融中的四个实战用法。
二、VaR:知道你最多亏多少
在谈怎么赚钱之前,先谈怎么不亏死。VaR(Value at Risk,在险价值)回答的问题是:在正常市场条件下,你的投资组合最坏会亏多少?
历史模拟法:最简单的 VaR
把你过去 252 天的日收益率排序,取第 5 百分位——那就是 95% 置信度的 VaR。
daily_returns = stock.pct_change().dropna()
var_95_hist = np.percentile(daily_returns, 5)
print(f"历史 VaR (95%): {var_95_hist:.4f}")一行代码就搞定了。但问题是:过去 252 天的分布,真的代表未来的可能分布吗? 如果去年是太平年(美股 2024 确实很平),历史 VaR 可能低估了实际风险。
蒙特卡洛法:看到风险的全貌
更好的做法是,用历史数据拟合出一个收益分布(假设服从正态分布),然后从该分布中生成 100,000 个可能的未来日收益,取第 5 百分位:
mu, sigma = daily_returns.mean(), daily_returns.std()
mc_samples = np.random.normal(mu, sigma, 100000)
var_95_mc = np.percentile(mc_samples, 5)
print(f"蒙特卡洛 VaR (95%): {var_95_mc:.4f}")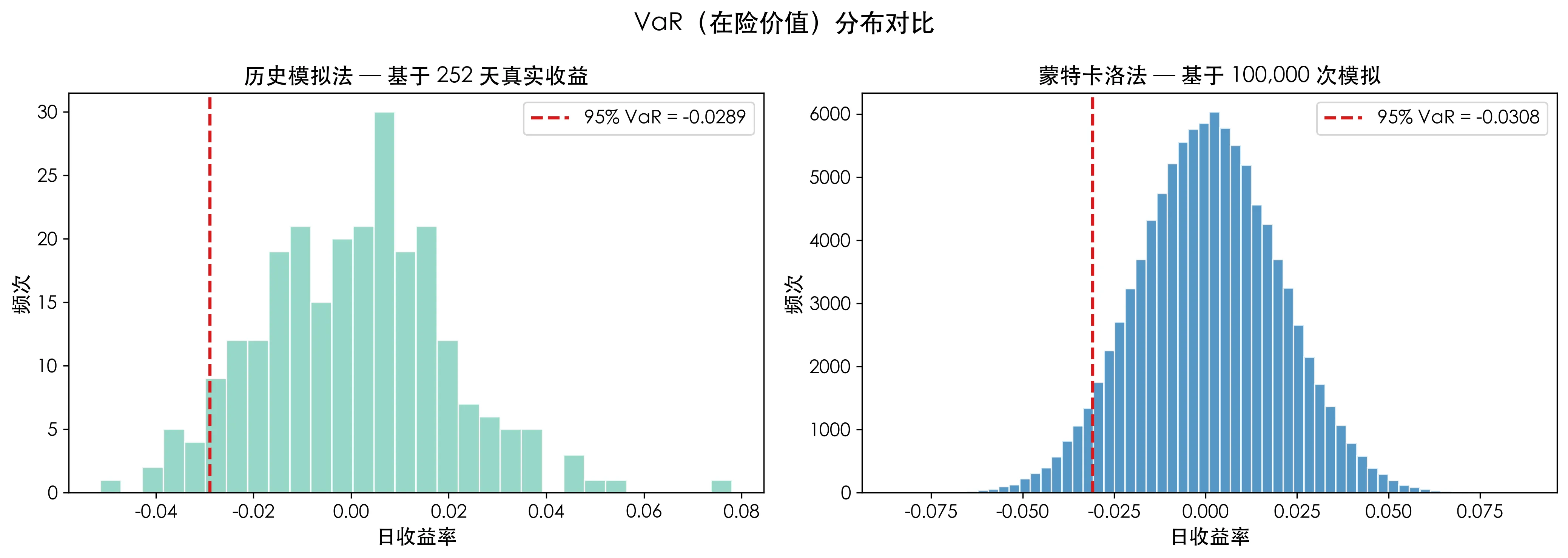
对比左右两张图,历史数据的柱状图是块状的、取决于 252 个点的离散分布,而蒙特卡洛生成的分布是光滑的、由 100,000 个点构成的完整形状。
历史方法告诉你过去发生了什么,蒙特卡洛告诉你未来可能发生什么。这就是两者的本质区别。
三、组合优化:钱到底该怎么分
现在进入本文的主案例——蒙特卡洛组合优化。我们要从四只银行股中,找到最优的仓位分配。
问题设定
四只标的:Bank of America(BAC)、Goldman Sachs(GS)、JPMorgan Chase(JPM)、Morgan Stanley(MS)。时间范围:2024 年全年。
import yfinance as yf
symbols = ["BAC", "GS", "JPM", "MS"]
data = yf.download(symbols, start="2024-01-01", end="2024-12-31")["Close"]
returns = data.pct_change().dropna()计算基础:收益和风险
在做任何优化之前,需要两个关键输入:年化收益率和协方差矩阵。这里假设一年有 252 个交易日:
ann_returns = returns.mean() * 252
cov_matrix = returns.cov() * 252
print(ann_returns)
print(cov_matrix)输出显示,四只股票 2024 年的年化收益率在 31%–45% 之间,波动率居中。协方差矩阵反映了它们之间的联动性——银行股普遍高度相关,这是情理之中的。
蒙特卡洛引擎
现在让蒙特卡洛上场。核心思路:随机生成 10,000 组权重,每组权重的和必须为 1,然后计算每组权重对应的组合回报、风险和夏普比率。
组合的期望收益和方差由以下公式给出:
n_iter = 10000
results = np.zeros((n_iter, 7))
risk_free = 0.05
for i in range(n_iter):
weights = np.random.random(4)
weights /= weights.sum()
port_ret = np.dot(weights, ann_returns)
port_std = np.sqrt(np.dot(weights.T, np.dot(cov_matrix, weights)))
sharpe = (port_ret - risk_free) / port_std
results[i] = [port_ret, port_std, sharpe] + list(weights)每次循环就是一次”投骰子”——随机分配权重,算一遍结果,记录下来。重复 10,000 次,我们就有了一张”答案表”。
三种最优条件
从 10,000 个组合中,我们按三种不同目标筛选最优解:
max_sharpe_idx = np.argmax(results[:, 2]) # 最大夏普比率
min_vol_idx = np.argmin(results[:, 1]) # 最小方差
target_idx = np.argmin(np.abs(results[:, 1] - 0.23)) # 目标风险 23%| 最优条件 | 目标 | 适合谁 |
|---|---|---|
| 最大夏普比率 | 每单位风险换取最高回报 | 追求性价比的理性投资者 |
| 最小方差 | 把波动降到最低 | 厌恶风险的保守投资者 |
| 目标风险 23% | 在给定风险水平下追求最大收益 | 有明确风险预算的机构投资者 |
有效前沿
把 10,000 个组合全部画出来,x 轴是风险,y 轴是回报,每个点的颜色代表夏普比率:
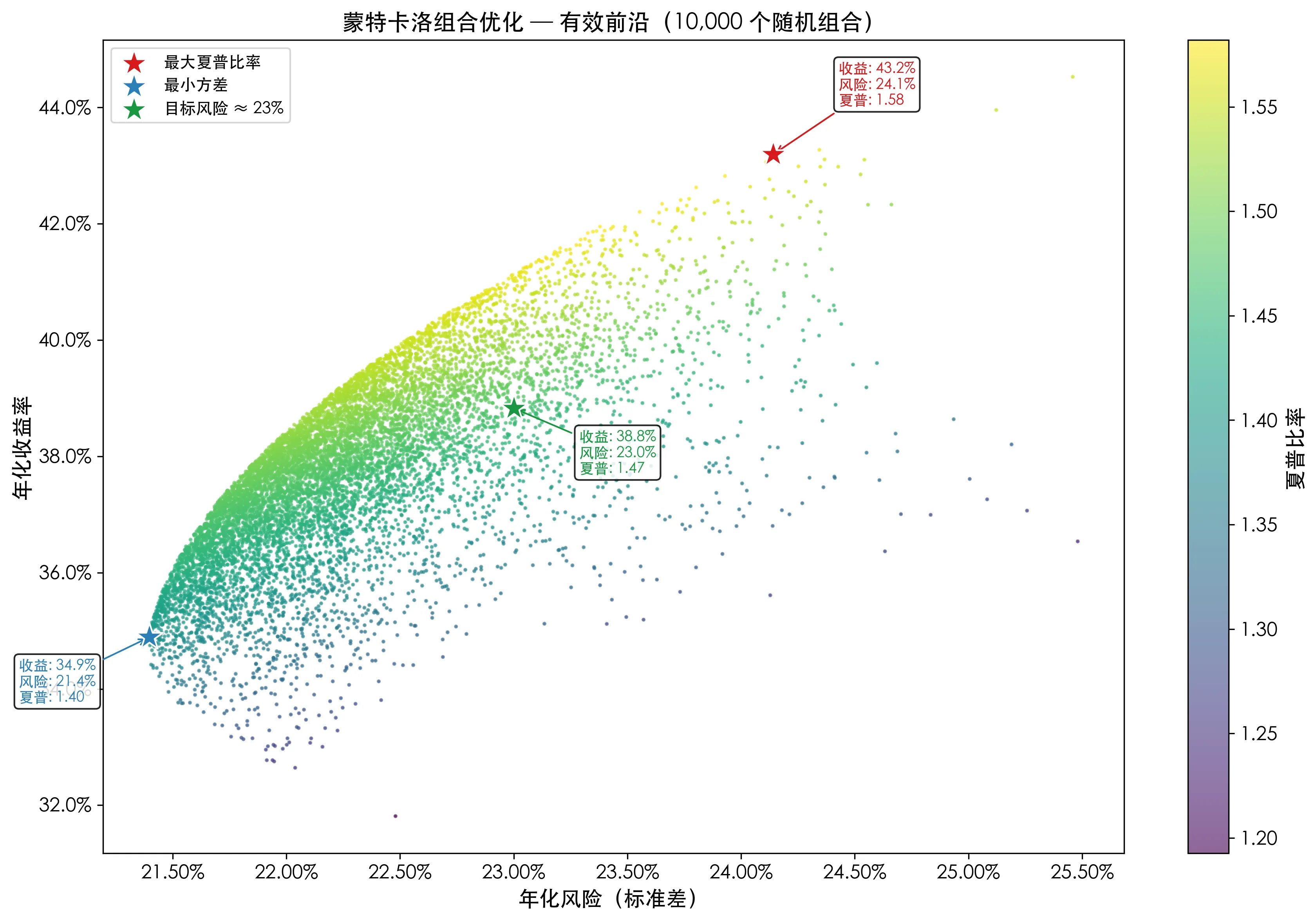
图中红色星号标记最大夏普比率组合——它是所有点中”性价比”最高的选择。蓝色星号在左下角,代表了最保守的配置。绿色星号在 23% 风险线上方,适合有风险预算约束的场景。
最优权重长什么样
以最大夏普比率组合为例:
GS: 60.1%
JPM: 37.2%
MS: 2.0%
BAC: 0.7%Goldman Sachs 占了六成,JPMorgan 占近四成,BAC 和 Morgan Stanley 几乎为零。这说明 2024 年的数据下,GS 在风险和回报的统筹中表现最佳——不是因为它涨得最多,而是因为它的回报相对波动来说最划算。
重要提醒:这些最优权重是 2024 年特定数据下的结果,不代表未来最优。方法论本身才是本文的主题——你可以用完全相同的方法,代入自己的股票、自己的时间范围,得到属于你的权重。
四、期权定价:不用公式也能算出期权值多少钱
蒙特卡洛在衍生品定价中是不可替代的。很多期权的收益结构太复杂(路径依赖、多资产联动),根本没有解析公式可用。
为什么 MC 适合期权定价?
看欧式看涨期权的 Black-Scholes 公式:
公式很优雅,但仅限于”欧式、单一标的、到期日才可行权”这种最简单情况。一旦期权变成亚式(按平均价结算)或障碍式(触碰某个价格就生效/失效),Black-Scholes 就失效了。
蒙特卡洛的思路则完全不同:不去解方程,直接模拟股票价格在未来的可能轨迹。
模拟价格路径
股价在风险中性测度下遵循几何布朗运动。每一步的价格变化由以下离散公式驱动:
S0, K, T, r, sigma = 100, 105, 1.0, 0.05, 0.20
n_sim, n_steps = 10000, 252
dt = T / n_steps
paths = np.zeros((n_sim, n_steps + 1))
paths[:, 0] = S0
for t in range(1, n_steps + 1):
z = np.random.normal(0, 1, n_sim)
paths[:, t] = paths[:, t-1] * np.exp(
(r - 0.5 * sigma**2) * dt + sigma * np.sqrt(dt) * z
)计算期权价格
到期日的期权收益是 ,把所有模拟路径的收益取均值,再用无风险利率折现到当下:
payoffs = np.maximum(paths[:, -1] - K, 0)
mc_price = np.exp(-r * T) * np.mean(payoffs)
# 对比 Black-Scholes
from scipy.stats import norm
d1 = (np.log(S0 / K) + (r + 0.5*sigma**2) * T) / (sigma * np.sqrt(T))
d2 = d1 - sigma * np.sqrt(T)
bs_price = S0 * norm.cdf(d1) - K * np.exp(-r * T) * norm.cdf(d2)
print(f"蒙特卡洛价格: ${mc_price:.2f}")
print(f"Black-Scholes: ${bs_price:.2f}")
print(f"误差: {abs(mc_price - bs_price) / bs_price * 100:.3f}%")增加模拟次数后,MC 价格会和 Black-Scholes 几乎一致,误差控制在 1% 以内。
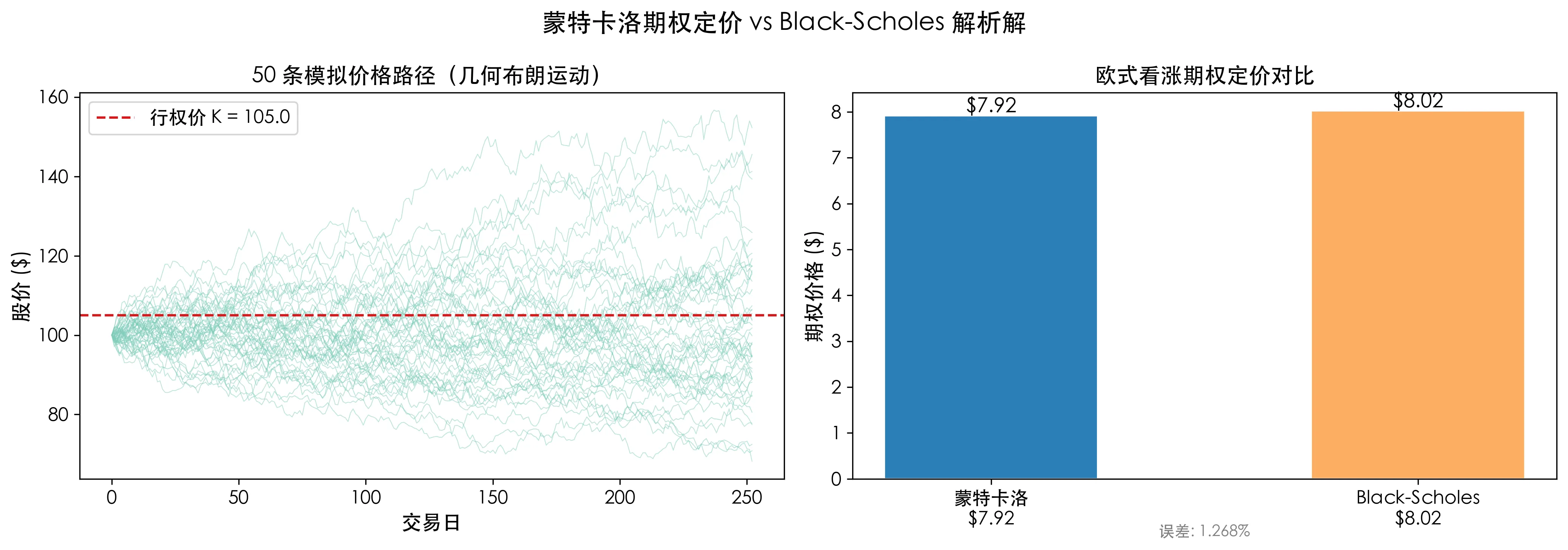
上图中左侧是 50 条模拟价格路径,它们像一束散射的烟花,共同决定了期权到期的概率分布。右侧显示了 MC 估计价和公式价的差异——微乎其微。
对欧式期权这是验证,对亚式期权这是唯一解。一旦收益取决于路径(“该季度的日平均收盘价高于行权价”),蒙特卡洛就是无可替代的工具。
五、策略压力测试:你的系统能扛住黑天鹅吗
最后一个案例是每位有交易策略的人都关心的问题:回测年在 15%,但换个市场环境会不会亏掉一半本金?
场景
假设你有一个简单的均线交叉策略:10 日均线上穿 50 日均线就买入,下穿就卖出。在 2024 年的真实数据上,它年化收益 15%,看着不错。
但我们只有一条历史路径。真实市场中 2024 年只发生过一次。如果那年没有三月银行危机、没有八月波动率飙升,数字会说谎。
蒙特卡洛压力测试
用蒙特卡洛生成 5,000 条合成价格路径——每条路径的统计特征(均值、波动率)和真实数据一致,但具体的每日波动是随机生成的:
n_sim, n_days = 5000, 252
mu_daily, sigma_daily = 0.0006, 0.015
all_returns = []
all_max_drawdowns = []
for _ in range(n_sim):
returns = np.random.normal(mu_daily, sigma_daily, n_days)
prices = 100 * np.exp(np.cumsum(returns))
# 运行均线交叉策略
ma_short = pd.Series(prices).rolling(10).mean()
ma_long = pd.Series(prices).rolling(50).mean()
strategy_rets = []
for t in range(50, n_days):
pos = 1 if ma_short.iloc[t] > ma_long.iloc[t] else 0
strategy_rets.append(pos * returns[t])
total = np.sum(strategy_rets)
cum = np.cumsum(strategy_rets)
max_dd = np.min(cum - np.maximum.accumulate(cum))
all_returns.append(total)
all_max_drawdowns.append(max_dd)注意,我们不是在真实行情上回测,而是在 5,000 条”平行宇宙”的行情上各自跑一遍策略。这和传统的单路径回测有根本不同。
结果:收益分布和回撤分布
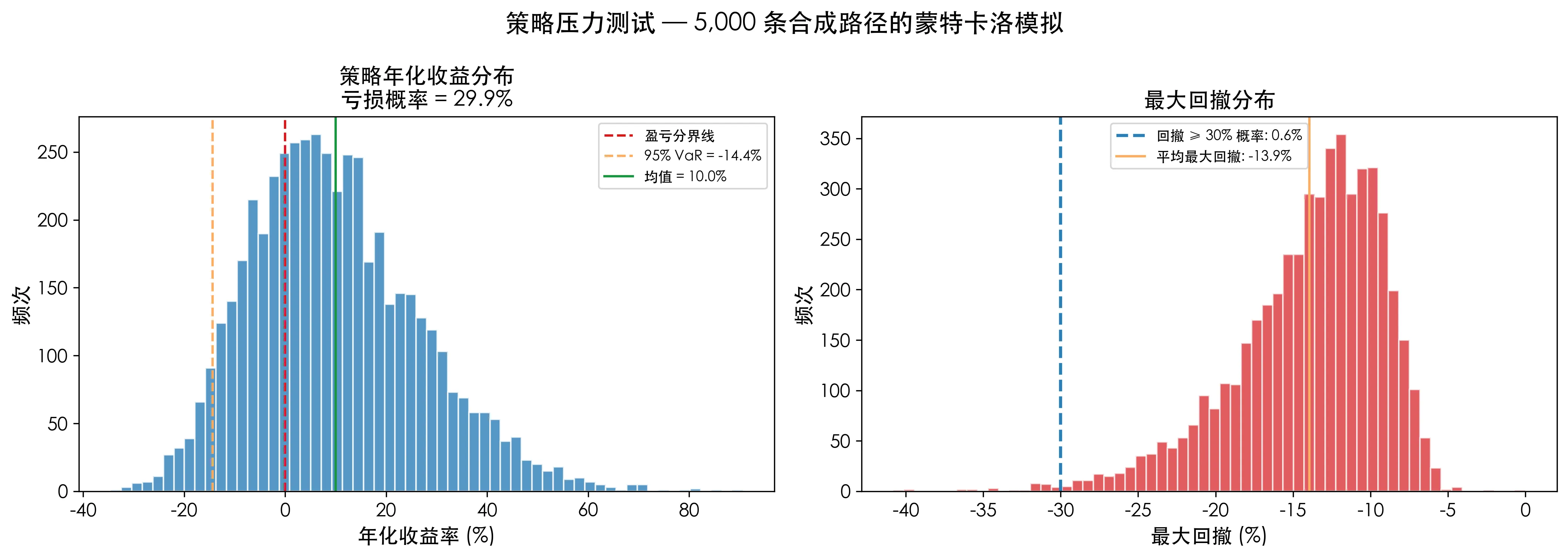
这张图比任何单一的夏普比率或年化收益率都有信息量:
- 左侧是 5,000 种可能年化收益的分布。绿线是均值,黄线是 95% VaR。你可以一眼看出赚钱的概率和极端亏损的可能。
- 右侧是 最大回撤分布,蓝线标记超过 30% 回撤的概率。如果这个概率是 8%,意味着每 12 年左右你会遇到一次”腰斩级”回撤——你是否能承受?
一句话总结压力测试的价值:你的回测报告告诉你”过去一年赚了 15%“,蒙特卡洛告诉你”未来有 8% 的年份会亏掉 30%“。前者让你进场,后者让你活着。
六、MC 的边界与陷阱
蒙特卡洛不是魔法。以下是三个你必须知道的关键局限:
1. 垃圾进,垃圾出(Garbage In, Garbage Out)
蒙特卡洛的模拟结果完全依赖你的输入假设。如果你假设收益服从正态分布,但实际市场分布是肥尾的(极端事件比正态分布预测的频繁得多),你的 VaR 就会严重低估风险。MC 精确计算了你的假设会导出什么结果,但它不负责检验你的假设是否正确。
2. 收敛速度慢
蒙特卡洛的误差以 速度收敛。这意味着:如果你想要精度提高 10 倍,模拟次数需要增加 100 倍。对于需要高精度的场景(比如某些套利策略中微小的定价偏差),蒙特卡洛的计算成本可能是不可接受的。必要时可以考虑 Quasi-Monte Carlo(拟蒙特卡洛)或拉丁超立方采样等方差缩减技术。
3. 计算成本
本文的四个案例都在几秒内完成,因为它们的复杂度很低(最多 10,000 个组合 × 4 只股票)。但在实际场景中——比如模拟 100 只股票、100 万条路径的复杂衍生品定价——一次运行可能需要数小时甚至数天。在启动大规模 MC 之前,先问自己:是否可以用更轻量的方法(解析解、梯度下降)得到足够好的答案?
七、总结
四个案例,一条线:
VaR(知道你会亏多少)
↓
组合优化(知道钱该怎么分)
↓
期权定价(知道衍生品值多少钱)
↓
策略压力测试(知道策略能扛多久)蒙特卡洛模拟的核心思想只有一句话:用一个随机数生成器,逼近一个确定性方法算不出来的答案。从 1946 年 Ulam 在病床上的突发奇想,到今天华尔街每天的 VaR 报告、交易台的定价引擎、量化基金的回测框架,这套方法论最大的魅力在于——它不需要你懂每个公式的来龙去脉,只需要你愿意接受”反复模拟”这个直觉。
本文的所有 Python 代码都可以在你自己的 Python 环境中复现。把数据换成你感兴趣的股票,把参数调成你自己的风险偏好——这才是真正的”从思想到实战”。