1 前言
Awk 是 Linux 及 Unix 环境中现有的最强大的数据处理引擎之一。它提供了极其强大的功能:正则表达式匹配、数学运算符、控制流语句、进程控制语句,甚至内置变量和函数。你可以看到,它几乎具备了一门完整语言所应有的全部优雅特性。实际上,awk 是一门隐藏在命令行中的编程语言。借助它,我们可以轻松实现数据排序、数据处理、报表生成等许多强大功能。
2 工作原理
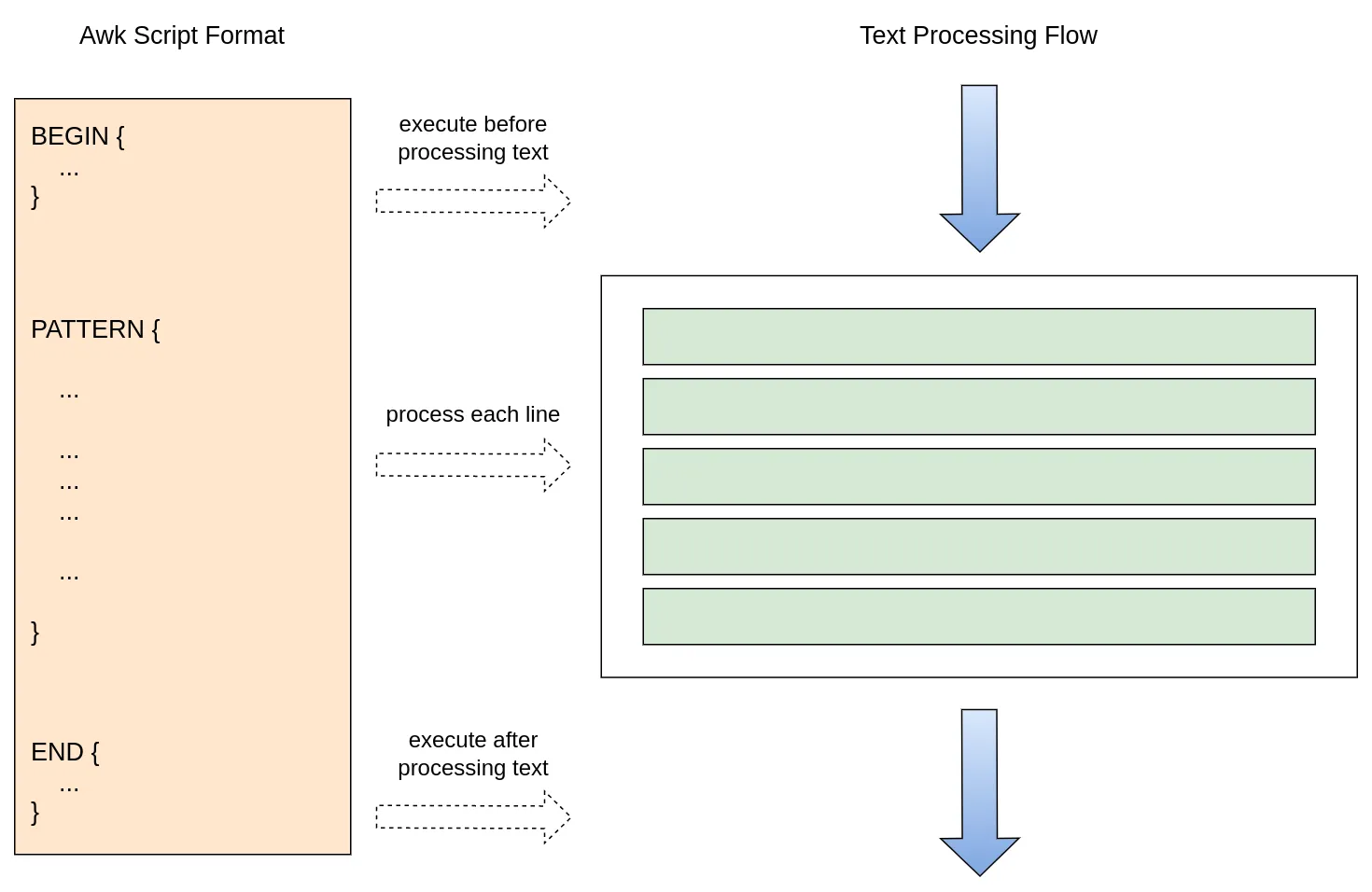
如下图所示,awk 脚本由三部分组成,分别对应文本处理的三个步骤。其中,BEGIN 代码块会在处理文本之前执行,中间代码块用于处理模式表达式(pattern expression)匹配到的文本行,END 代码块则可以在文本处理完毕后执行一些收尾操作。这三部分都是可选的,无论缺失哪个代码块,其余代码块仍会按照文本处理流程正常执行。
3 基本用法
awk 脚本可以直接通过参数传递给 awk 命令,如下所示,需要指定待处理的文件路径。
$ awk 'BEGIN{}pattern{commands}END{}' {text file}如果脚本比较复杂,也可以将脚本单独存放在一个文件中,然后使用 -f 参数指定脚本文件的位置。
$ awk -f {script file} {text file}4 内置变量
| 内置变量 | 含义 |
|---|---|
| $0 | 整行内容 |
| $1-$n | 当前行的第 1 至 n 个字段 |
| NF | 当前行的字段数,即有多少列 |
| NR | 当前行的行号,从 1 开始计数 |
| FNR | 处理多个文件时,每个文件的行号单独计数,从 0 开始 |
| FS | 输入字段分隔符,未指定时默认按空格或 Tab 键分割 |
| RS | 输入行分隔符,默认是回车换行 |
| OFS | 输出字段分隔符,默认是空格 |
| ORS | 输出行分隔符,默认是回车换行 |
假设我们有以下测试数据:
$ cat demo1.txt
Name Gender Age Education
John Male 25 Bachelor
Mike Male 34 Doctoral
Lily Female 26 Bachelor
David Male 29 Master
$ cat demo2.txt
Name,Gender,Age,Education
John,Male,25,Bachelor
Mike,Male,34,Doctoral
Lily,Female,26,Bachelor
David,Male,29,Master(1)只打印 demo1 文件的第 1、2 列内容。
$ awk '{print $1,$2}' demo1.txt
Name Gender
John Male
Mike Male
Lily Female
David Male注:由于不需要在文本处理前后做额外操作,此处省略了 BEGIN 和 END 代码块。
(2)打印 demo1 文件每行的列数。
$ awk '{print NF}' demo1.txt
4
4
4
4
4(3)打印 demo1 文件,并在每行前面加上行号。
$ awk '{print NR,$0}' demo1.txt
1 Name Gender Age Education
2 John Male 25 Bachelor
3 Mike Male 34 Doctoral
4 Lily Female 26 Bachelor
5 David Male 29 Master(4)只打印 demo2 文件中第 1 列和第 2 列的内容。
$ awk -F ',' 'BEGIN{OFS=","}{print $1,$2}' demo2.txt
Name,Gender
John,Male
Mike,Male
Lily,Female
David,Male注:由于默认列分隔符是空格,所以在处理前需要指定新的列分隔符。
5 模式匹配
有时我们不需要处理每一行,而只处理特定的行。awk 提供了非常强大的模式匹配工具,不仅可以通过正则表达式来匹配,还可以通过运算符来匹配,或者将两者结合实现更复杂的匹配。下面列出了可用的运算符列表。
| 符号类型 | 符号 | 含义 |
|---|---|---|
| 关系运算符 | < | 小于 |
| > | 大于 | |
| <= | 小于等于 | |
| >= | 大于等于 | |
| == | 等于 | |
| != | 不等于 | |
| ~ | 匹配正则表达式 | |
| !~ | 不匹配正则表达式 | |
| 逻辑运算符 | && | 与 |
| || | 或 | |
| ! | 非 |
(1)只打印包含 Mike 的行。
$ awk '/Mike/{print $0}' demo1.txt
Mike Male 34 Doctoral(2)只打印学历为本科的行。
$ awk '$4=="Bachelor"{print $0}' demo1.txt
John Male 25 Bachelor
Lily Female 26 Bachelor(3)只打印年龄小于 30 的行。
$ awk '$3<30{print $0}' demo1.txt
John Male 25 Bachelor
Lily Female 26 Bachelor
David Male 29 Master(4)只打印年龄小于 30 且学历不是本科的行。
$ awk '$3<30&&$4!="Bachelor"{print $0}' demo1.txt
David Male 29 Master6 控制流语句
条件语句格式:
# 条件语句 1
if (condition) {
...
}
# 条件语句 2
if(condition) {
...
} else {
...
}
# 条件语句 3
if(condition 1) {
...
} else if(condition 2) {
...
} else {
...
}循环语句格式:
# for 循环示例
for(i = 0; i < 100; i++) {
...
}
# while 循环示例
while(condition) {
...
}
# do-while 循环示例
do {
...
} while(condition)(1)计算以下学生的平均成绩,只打印平均成绩大于 90 的学生姓名和平均成绩。
$ cat demo3.txt
Michael 80 90 96 98
David 93 98 92 91
Emily 78 76 87 92
Sarah 86 89 68 92
Kevin 85 95 75 90
Jessica 78 88 98 100
$ cat demo.awk
{
avg = ($2 + $3 + $4 + $5) / 4
if (avg > 90) {
print $1,avg
}
}
$ awk -f demo.awk demo3.txt
Michael 91
David 93.5
Jessica 91(2)计算 1+2+3+4+…+100 的总和,分别用 for、while、do-while 循环实现。 使用 for 循环实现:
$ cat for.awk
BEGIN {
for(i = 1; i <= 100; i++) {
sum += i
}
print sum
}
$ awk -f for.awk
5050使用 while 循环实现:
$ cat while.awk
BEGIN {
while(i <= 100) {
sum += i
i++
}
print sum
}
$ awk -f while.awk
5050使用 do-while 循环实现:
$ cat doWhile.awk
BEGIN {
i = 1
do {
sum += i
i++
} while(i <= 100)
print sum
}
$ awk -f while.awk
50507 字符串函数
| 函数 | 说明 | 返回值 |
|---|---|---|
| length(str) | 计算字符串长度 | 字符串的长度 |
| index(str1,str2) | 在 str1 中查找 str2 的位置 | 位置索引,从 1 开始计数 |
| tolower(str) | 将字符串转为小写 | 转换后的小写字符串 |
| toupper(str) | 将字符串转为大写 | 转换后的大写字符串 |
| substr(str,m,n) | 从第 m 个字符开始截取 n 个字符 | 截取到的子字符串 |
| split(str,arr,fs) | 按照字段分隔符 fs 将字符串分割为子字符串,并存储到数组 arr 中 | 切割后的子字符串数量 |
| match(str,RE) | 在 str 中搜索匹配正则表达式 RE 的子字符串,返回匹配位置 | 匹配位置 |
| sub(RE,RepStr,str) | 在 str 中搜索第一个匹配 RE 的子字符串并替换为 RepStr,返回替换次数(1 或 0) | 替换次数 |
| gsub(RE,RepStr,str) | 在 str 中搜索所有匹配 RE 的子字符串并替换为 RepStr,返回总替换次数 | 替换次数 |
(1)在字符串 “I have a dream” 中搜索 “ea” 的出现位置。
$ awk 'BEGIN{str="I have a dream"; location=index(str,"ea"); print location}'
12(2)将字符串 “Hadoop is a bigdata Framework” 全部转为小写。
$ awk 'BEGIN{str="Hadoop is a bigdata Framework"; print tolower(str)}'
hadoop is a bigdata framework(3)在字符串 “I got 90 on the test” 中搜索第一个数字出现的位置。
$ awk 'BEGIN{str="I got 90 in the test"; location=match(str,/[0-9]/); print location}'
7(4)从字符串 “I got 90 on the test” 的第 3 个字符开始截取 6 个字符。
$ awk 'BEGIN{str="I got 90 in the test"; print substr(str,3,6)}'
got 90(5)将字符串 “I got 90 on the test” 中第一个匹配的数字串替换为 @ 符号。
$ awk 'BEGIN{str="I got 90 in the test"; sub(/[0-9]+/,"@",str); print str}'
I got @ in the test8 总结
本文详细介绍了 awk 作为工具的基本用法,了解了 awk 的工作原理,并知道了它擅长的一些领域。实际上,将 awk 描述为 Linux 环境下的一个命令行工具并不准确。它本质上是一门编程语言。它不仅拥有内置变量和函数,还具备流程控制语句,我们甚至可以自定义变量和函数。它的语法借鉴了 C 语言的编程风格,并具有强大的动态类型推断能力,因此比 Shell 脚本更容易编程。确实,在很多方面,awk 脚本可以替代 Shell 脚本来帮助我们完成一些自动化的事情,所以熟练掌握 awk 可以有效提高我们的工作效率。